This project was completed as part of CSE-211 with Tyler Sorenson. Thanks for the great class!
It is not a controversial statement that we care very deeply about performance. The programs that we write must run efficiently on a diverse set of hardware whose local software state can be equally as diverse. Similarly, program behavior varies over its lifetime, evolving workloads result in very different “hot spots” in both instruction execution and memory usage in our programs. One of the primary goals of compilater backends is to not only make a program actually executable but to also make it fast, and to make it fast in a lot of different machines. However, this race towards performance at all costs has resulted in a truism that doesn’t necessarily hold in all circumstances. The truism that compiled applications tend to be overwhelmingly faster in pretty much all circumstances. This attitude is generally summarized in the belief that compiled languages are fast while interpreted or JIT-compiled languages are slow. While I admit that I’m setting up a rhetorical staw man to construct my argunment this is not a wholly uncommon opinion. Attitudes such as this not only ignore the generally unseen and undiscussed cost1of compilation in complex environments but also make it difficult to leverage the robust amount of work that has gone into profile guided optimizations which are easier to implement in interpreter runtimes.
A Motivating Example
A Straw-man
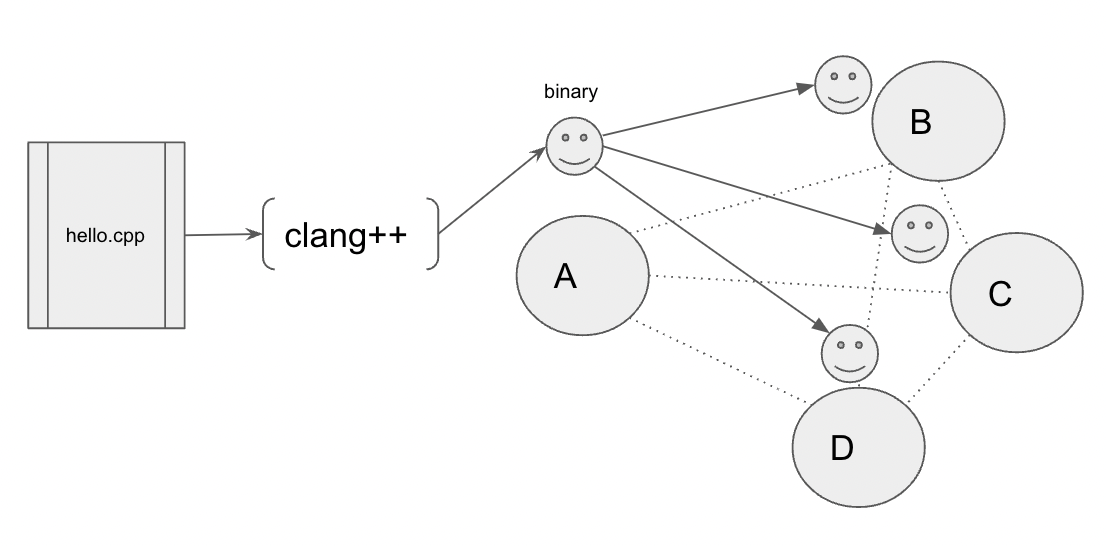
The rare but frustrating deployment– Figure 1.
Let’s start with Figure 1. Say you have a program you want to run in some other machine in your cluster. It can be a program you want to only run in another machine once as that machine has some raw data that you care to extract, or perhaps you want to run an embarrassingly parallel workload in which you need to run a lot equivalent programs in a large cluster. You happen to be lucky enough to be working with a new cluster that only has CPUs from a single provider from a single product line with equivalent low level features. In this scenario the process towards compiling and deploying your application is quite straightforward. You simply provide your compiler the compilation target information it needs 2 and any dependencies and flags it needs to compile and then you run it! For the final deployment of your binaries you have two choices really, you either copy them over yourself over the network or you are likely to have some subsystem that does this for you 3.
Now let’s step away from dream land into a (slightly more) realistic scenario.
It gets worse!– Figure 2.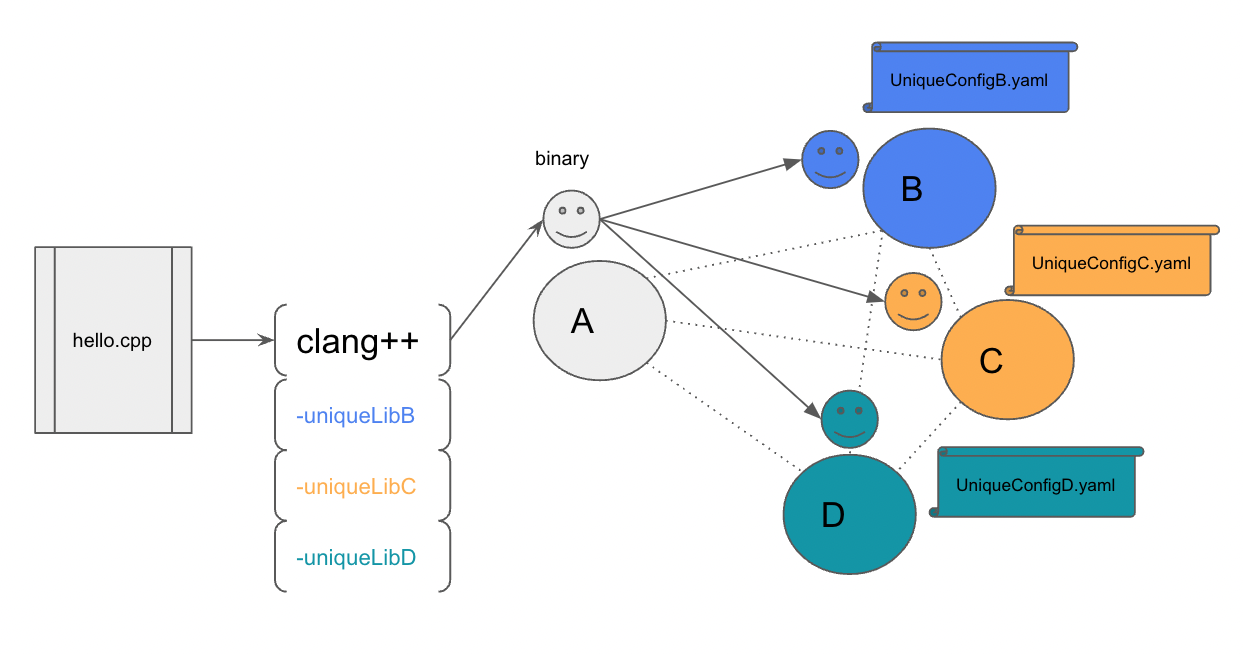
On top of all of this your applications now also have some unique special configuration that are very important for your runtime but also changes your application performance. If you didn’t have such a heterogenous environment you could maybe do a couple profile runs with your configuration and tune your compiler flags and other inputs to get the best possible execution, but you aren’t in such a nice world. Instead you would now need to fine tune what’s essentially three highly divergent applications, each on different hardware.
Well at least deploying your binaries is relatively the same, but again maybe not. Now you have to keep track of multiple different binaries that all must be delivered to different locations. Again, some subsystem might help you out but they are generally are not perfect, a single misconfiguration is all you need and you’re left debugging a job that was supposed to start running hours ago.
Admittedly this is a very contrived scenario. It’s unlikely that something this bad happens often, and there are a lot of tools available that make every step of this process less painfule. Docker is perfect for many applications, and removes this problem entirely by packaging your deployment environment with your application. The downside with that approach is that you definitely lose out on some performance, and similarly there are a lot of large scale applications that arent designed to run on a containerized environment. In the HPC world, Slurm has an okay system for managing heterogenous compute and can help in linking complex dependencies in your compilation. That doesn’t really address unique program behavior that might arise due to some distinct configuration, but well we are often satisfied without trying to do some fancy runtime optimizations if we get decent performance.
One way or another, by the nature of our increasingly heterogenous environment we’ve increased our compilation and coordination burden. This burden is especially heavy if the job you want to run doesn’t really need to leverage economies of scale inherent to compilation ie. compile once run as many times as you want. You might also be in an environment in which simple recompilation is not exactly a good solution, one can take only so many coffee breaks after all.
A Pitch

It gets worse!– Figure 3.
A potential solution to most of the aforementioned problems is to pushdown the “compilation” step closer to the final execution of the program. Instead of cross compiling towards multiple different targets at a single node and deploying accordingly, we can instead compile to LLVM Bitcode or LLVM IR and ship these intermediate files to their final destination.
Once at their targets, local instances of our compiler/interpreter infrastructure can consider job details4, carry out some static analysis, and look at local machine state to decide whether it is wiser to interpret/JIT or compile. In either case we simplify our cross compilation obstacles and facilitate the deployment coordination. Simultaneously, having a program’s IR in the same machine that is actually executing the code can give us access to the coveted world of runtime optimizations without needing to do any true source recompilation.
To do this we need a runtime that can intake LLVM IR programs, decide whether to interpret, JIT, or compile and immediately execute the program.
This doesn’t resolve difficulties associated with managing dependencies and libraries. Similarly, while compiler backends have gotten really good at recognizing the diverse world of hardware devices, a significant amount of work would likely still be needed to do this seamlessly.
The first step to really evaluate whether this is a viable solution is to compare the performance of interpreters, JIT Compilers, and compilation and execution. Most of this document will cover these experiments, and some other thoughts around how a robust decision mechanism can be built.
The Executor
every bad prototype needs an overly important name!
LLVM Project
The LLVM Project is the backbone of modern compiler infrastructure. Most modern systems toolchains depend in at least one tool that comes from the project, and I’m happy to continue this long tradition of building on their incredible hard work.
The LLVM project includes Clang, LLDB, and crucially for this project lli. Lli is an LLVM IR Interpreter and JIT Compiler. The core of this project will use these tools to quickly prototype a comparison program to figure out the viability of such a runtime.
The LLVM Project offers great support for creating new tools that use LLVM internals. This support lets you efficiently rewire LLVM together for whatever end you please. The final production of this kind of project would follow this approach to prevent any unnecessary overhead. However, as time is finite I opted for hacking together existing LLVM utilities to get my results.
Project Design
The Executor is a simple execution engine that when provided an LLVM Bitcode will interpret it, JIT it, and compile and execute it. This comes with some nice testing infrastructure that reports on each approach’s overall runtime. The current testing infrastructure also tries to account for any overhead that it’s own presence introduces. While overall execution numbers are probably not fully optimized all runs include the same accounted for overhead, so the results are comparable to one another.
This is the current state of the The Executor, as it stands it’s nothing more than some nice testing infrastructure. I do hope to evolve the project into its eventual direction of being able to dynamically decide on which execution path makes the most sense. Something to consider however is that we do have a pretty short decision budget. The more time we spend trying to figure out the best choice the more we lose in potential performance gains.
Thoughts on program runtime
How can we make predictions on program runtime without running into the halting problem? The answer is we can’t. But we can pretend certainty is overrated and our best shot is good enough. Now that we’ve dispensed ourselves with any epistemological anxieties we can move on to some practical techniques that can help us go very far.
Generally, there are two broad categories that can help us figure out the runtime of programs, benchmarking and analysis.
With benchmarking the only thing we need to is to develop a corpus of applications and inputs that are hopefully representative of any potential programs we see in the future. We can expect a program that falls under a benchmarking bucket with known inputs will behave similar enough to the benchmark. Things aren’t so easy of course, with this methodology we run right into the classification problem. How do we even know if a program goes in one bucket and not the other? How do we build these categories? How do we analyze relatively low level LLVM to make categorical conclusions about program runtimes? How do we avoid the mistakes of everyone that has tried to do this in the past5 (and there is a decent number of people who’ve tried)? The categorical problem is less significant in the case that we only really make decisions based on benchmarks for programs we have seen before, or maybe the programs previous versions. This is less useful in the face of things we haven’t seen before but can still be a valid approach.
With benchmarking found wanting we turn to analysis. We can conclude certain things about a program’s runtime by looking at its inputs and analyzing its LLVM IR. This is probably not so hard for certain aspects of program behavior. For example, loops nested many levels deep with a large number of iterations are probably going to take some more time than some non looping instructions. However, the problem explodes in complexity quickly. There is also the problem that the more analysis we do the more we burn our ever shortening decision budget. It is also redundant work that the Compiler is likely to repeat in the future as any inspection steps are likely going to look similar to analysis passes that we see in compiler infrastructure.
There is no easy and “complete” solution here sadly.
Results
I wrote up a few programs and got a few from my Compilers coruse for this experiment. Each of these programs was run with the same testing infrastructure in the same machine with 100 executions to increase our measurement precision.
HelloWorld
The simplest of HelloWorld programs! I was not necessarily expecting the compiler to be faster but it did surprise how much faster the interpreter and the JIT compiler were. This first experiment does give us an indication of how much overhead compilation can introduce.
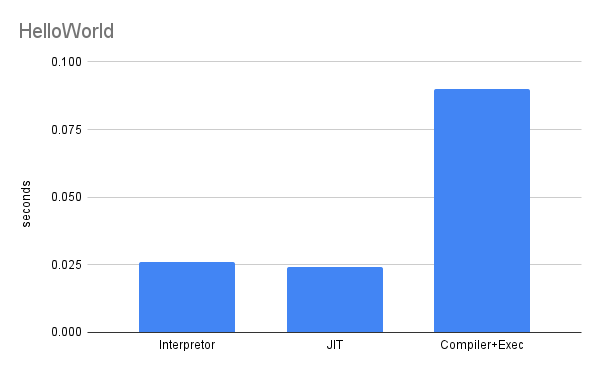
HelloWorld Bench– Figure 4.
Inefficient Loop and Local Value Numbering
The next experiment was to test out some programs in which compilers are famously helpful in. The Inefficient Loop program was composed of a loop which should be easy to interleave for better performance to leverage instruction level parallelism. While the Local Value Numbering program is simply a function call in which there is significant amounts of instructions that don’t really do anything 6 (like a variable declaration that never gets used). In the scope of local optimizations compilers are great at handling these, as they really efficiently remove all instructions of these types.
Again pretty surprising results! I was not expecting these to be as even as they are. I suspect that the LLVM Interpreter and JIT-Compiler do some local level optimizations as they go from module to module.
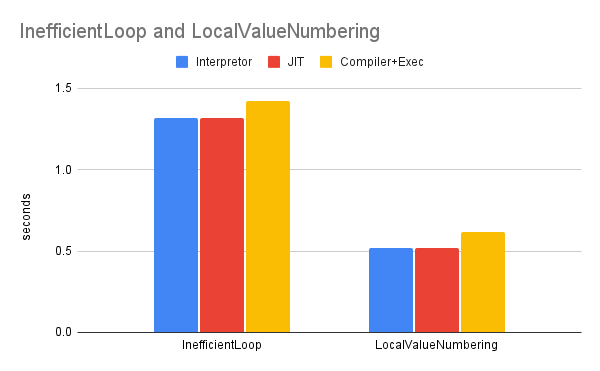
HelloWorld Bench– Figure 4.
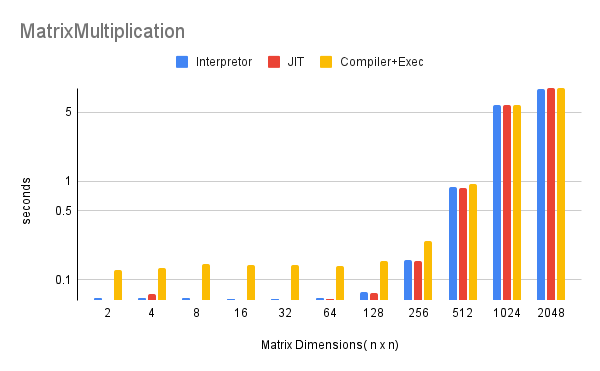
Matrix Multiplications
Out of all of the experiments this is the most interesting one. The interpreter and JIT-Compiler far outrun the Compiler until we start reaching larger and larger matrix sizes. This is the kind of result I hoped to see as there is a very clear cut between line in which the Compiler starts having equivalent performance to the interpreter and the JIT-Compiler. This experiment fully took 3-4 hours to run due to the overhead introduced by the extra executions to prevent outliers so I could not experiment past 2048x2048 dimensions, but its something I definitely want to try in the future. At large enough sizes will the compiler outrun the interpreter and JIT Compiler?
HelloWorld Bench– Figure 4.
Shortcomings
This exercise really only makes sense in one scenario, you want to deploy an application and run it only once on a machine you don’t know all the details ahead of time. In any case in which a binary compiled ahead of time is ran against an interpreted or jitted program, the compiled binary will win. It is only in the rare scenario in which the execution of a program immediately preceds its compilation in which an interpreter or a JIT compiler could outperform compiler performance.
There are some pretty significant shortcomings in how these benchmarks were carried out. There is the overhead that the testing infrastructure might’ve introduced, I tried to mitigate for this as much as possible but it’s unlikely I accounted for all of it. There is also caching behavior which is really hard to control for. During a few initial test runs there was definitely some caching behavior that improved program performance. I was not able to account for it properly for the final experiment, which does pollute the results. Under the scenario that I’ve constructed our programs should be interpreted, JITed, or compiled and executed during the first time they are deployed to a machine. Caching behavior should definitely be controlled for in the future. This is also a very limited set of applications! Truly considering this as any representation of actual runtime performance for the interpreter, JIT Compiler, and Compiler would be inaccurate. To properly evaluate these we would not only need a much larger set of applications but also more efficient testing infrastructure.
Future Work
- Executing a closure: I’m really interesting in the idea of investigating this idea not on whole programs but on smaller closures. By limiting the scope of the program the advantages of interpretation are likely that much more significant.
- Investigating the performance implications of dependencies and linking: Dependencies are a headache and can introduce a lot overhead outside of your control. There is a lot to investigate here.
- Actual decision making mechanism: Benchmarking or analysis either one is interesting but having an actual framework for when programs should be compiled or interpreted introduces a lot of potential.
- Evaluating different compilers: Particularly for non CPU architectures.
- Profiling: Profiling the interpreters and compilers to see where most of the overhead is actually spent.
- WASM: Look into WASM as a valid IR langauge over LLVM. Increasingly it seems that WASM will be the go to standard for shippable non-compiled programs.
Conclusions
While I tried to focus on three different applications of varying complexity, none of these applications really get at the core of our question. Is the benefit of compiler optmizations that can not be done in an interpreter or a JIT compiler worth it when speed of execution from compilation to deployment is the primary priority? We have not really answered this question. To do so we would need a set of applications that explictly contain the kind of scenarios in which a standard compiler could optimize in ways that an interpreter couldn’t. An example of this kind of optimization are compiler managed slab allocations, in which the compiler must have a full view of the program to determine all memory accesses that could be grouped together.
This is definitely only the first step in the dream of easy deployment and easy “shippable” code. These early results are encouraging and suggest that interpretation and JIT Compilation has gone a long way, and in some cases might be just as or more efficient than a traditional compile path. This argument however is limited to specific scenarios, as the place in which the compiler would truly shine would be with large programs with complex behaviors an interpreter or JIT compiler wouldn’t be able to optimize. Similarly, the moment you need to execute your program more than once precompiling your binary is the thing to do.
Bibliography
[1]“Creating an LLVM Project — LLVM 16.0.0git documentation.” https://llvm.org/docs/Projects.html (accessed Dec. 08, 2022).
[2]Lee, Jenq-Kuen, “LLVM Bitcode Introduction,” p. 17, 2013.
[3]C. Lattner and V. Adve, “LLVM: A compilation framework for lifelong program analysis & transformation,” in International Symposium on Code Generation and Optimization, 2004. CGO 2004., San Jose, CA, USA, 2004, pp. 75–86. doi: 10.1109/CGO.2004.1281665.
[4]A. Engelke and M. Schulz, “Robust Practical Binary Optimization at Run-time using LLVM,” in 2020 IEEE/ACM 6th Workshop on the LLVM Compiler Infrastructure in HPC (LLVM-HPC) and Workshop on Hierarchical Parallelism for Exascale Computing (HiPar), Nov. 2020, pp. 56–64. doi: 10.1109/LLVMHPCHiPar51896.2020.00011.
[5]“Runtime Execution Profiling using LLVM.” https://www.cs.cornell.edu/courses/cs6120/2019fa/blog/llvm-profiling/ (accessed Nov. 15, 2022).
[6]“The LLVM Compiler Infrastructure.” LLVM, Dec. 09, 2022. Accessed: Dec. 08, 2022. [Online]. Available: https://github.com/llvm/llvm-project
in developer hours more than anything ↩︎
almost all modern toolchains do this for you ↩︎
Yes, even if you are running it from a distributed file system it still needs to be copied over the network ↩︎
run once vs run many times ↩︎
and there is a decent number of people who’ve tried. In HPC you have a categorization of HPC applications, as described on this paper. As best as I know this didn’t really succeed as a categorization framework. ↩︎
like a variable declaration that never gets used. ↩︎